Top 10 Data Engineering Research Papers to read
Must read data engineering research papers including MapReduce, Google Filesystem, Spark


I have seen quite a lot of AI papers flooding around internet, and curious why data engineering papers was not shared enough. Today I am going to share top Data Engineering papers that are must read.

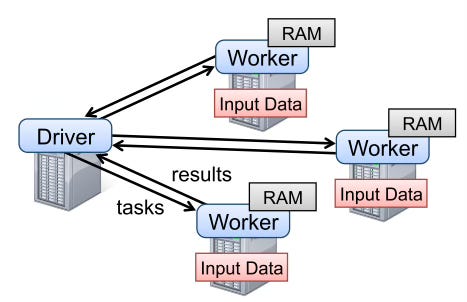
This paper from Google introduced a programming model and execution framework for processing large-scale data across distributed systems. By abstracting parallelization, fault-tolerance, and load balancing, MapReduce made distributed computing accessible to engineers and sparked the big data revolution.It is probably fair to say that half of the academia are now working on problems heavily influenced by MapReduce.
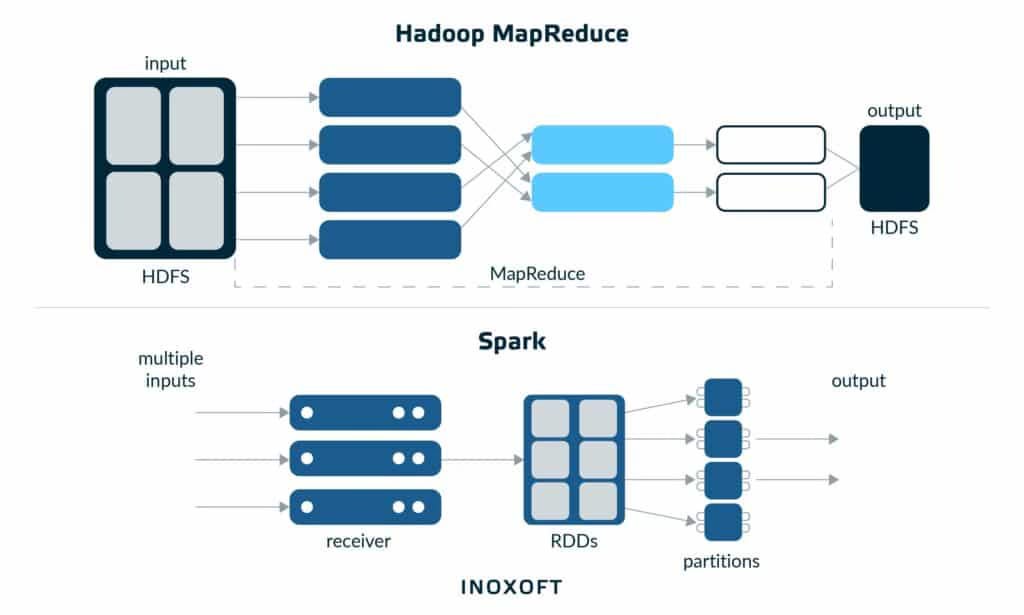
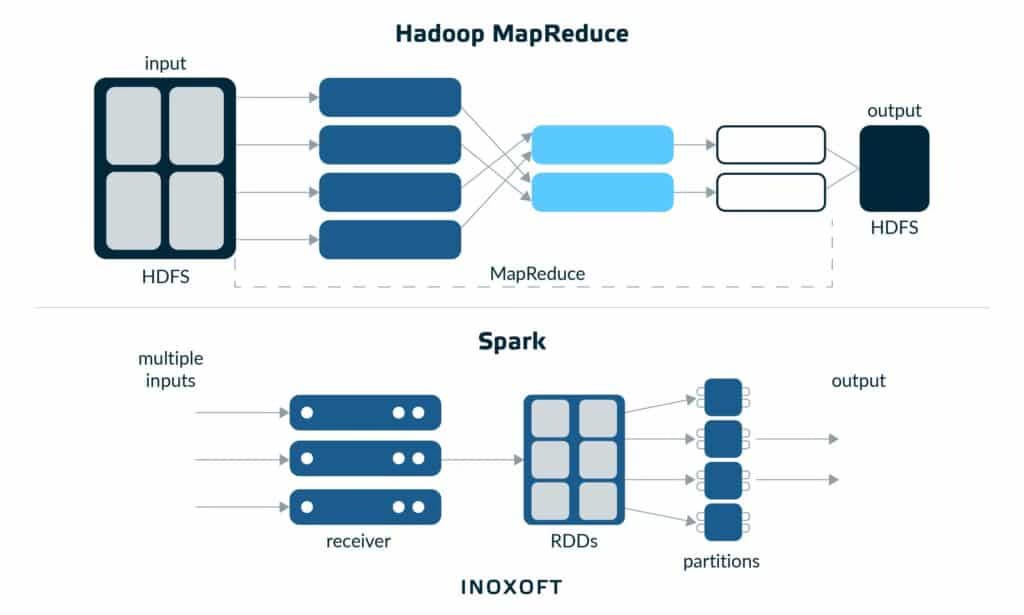
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing

This is the research paper behind the Spark cluster computing project at Berkeley. It represents RDDs as a key abstraction enabling fast, in-memory computations while maintaining fault tolerance. It revolutionized batch and iterative data processing by offering better performance and easier programming models than MapReduce.
This paper explores the design and performance of columnar storage formats, specifically how past ideas in database architecture are being revived and optimized for modern analytical workloads. It emphasizes the importance of vectorized execution and columnar encoding for big data systems.

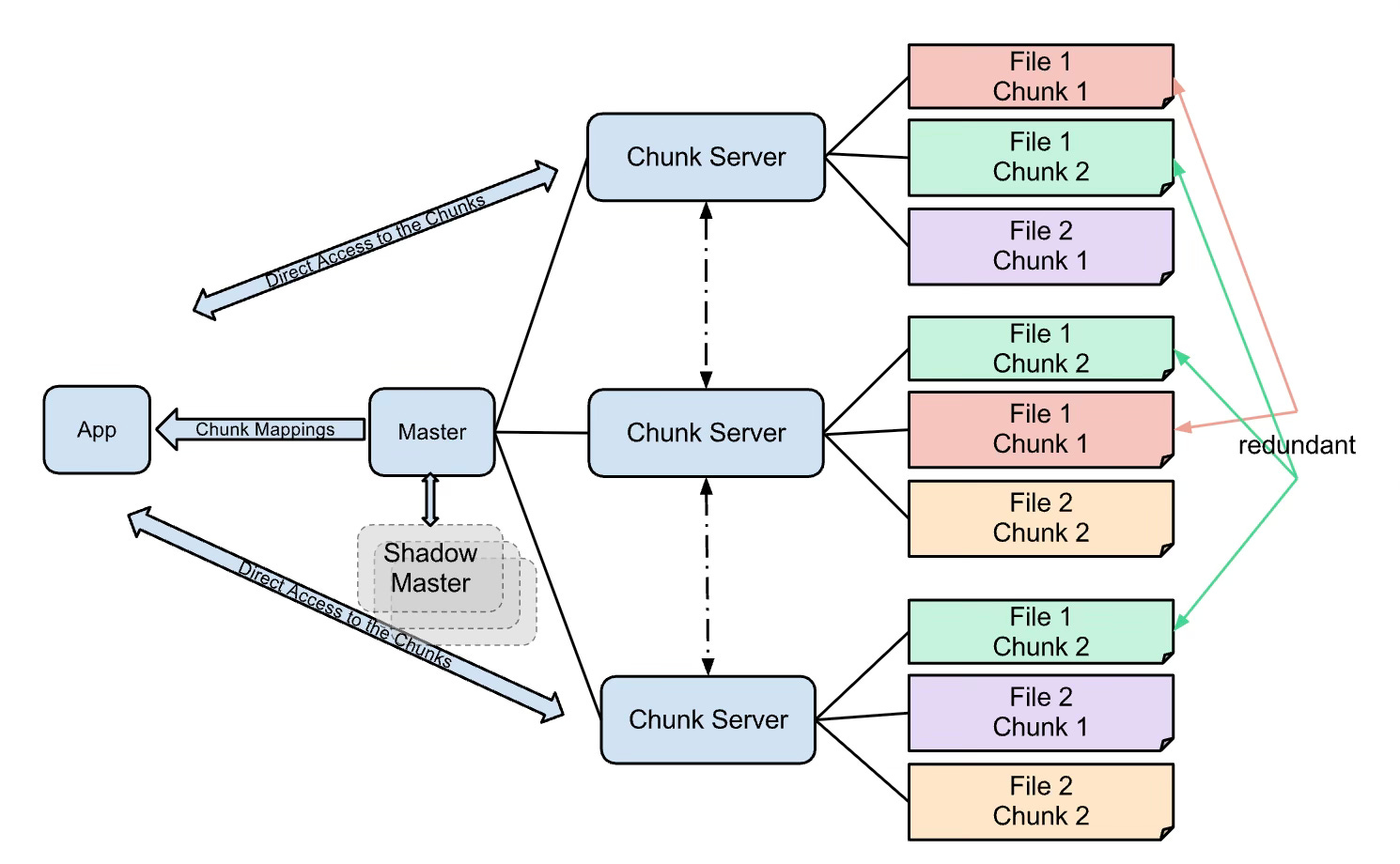
Google file system(source: brabalawuka's blog) A foundational work that details a scalable, distributed file system built to handle Google’s internal data needs. GFS is designed for fault tolerance, high throughput, and large files, and it laid the groundwork for systems like HDFS and Bigtable.
Shark: SQL and Rich Analytics at Scale
Shark extended Apache Spark to support SQL queries alongside complex analytics. It bridged the gap between fast in-memory computation and declarative query languages, making it possible to unify ETL, analytics, and machine learning workloads.More importantly, the paper discusses why previous SQL on Hadoop/MapReduce query engines were slow.
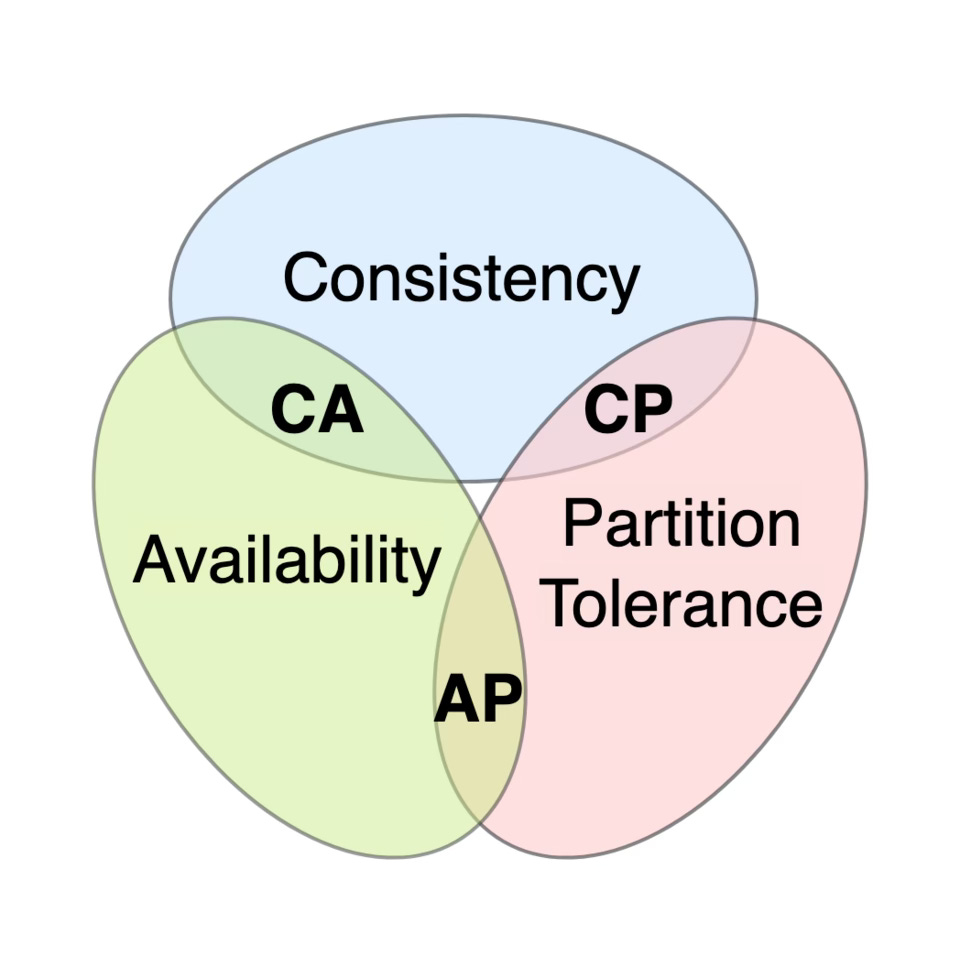
CAP Twelve years later: How the "Rules" have Changed

The CAP theorem, proposed by Eric Brewer, asserts that any networked shared-data system can have only two of three desirable properties: Consistency, Availability, and Partition-Tolerance. A number of NoSQL stores reference CAP to justify their decision to sacrifice consistency. A reflective piece that revisits the CAP theorem (Consistency, Availability, Partition Tolerance) a decade after its original formulation. It clarifies misconceptions, explores real-world implications, and offers a more nuanced understanding of trade-offs in distributed systems.
Architecture of a Database System

This survey paper dissects the major components and design principles of modern database systems, from storage and indexing to query processing and transaction management. It's a comprehensive blueprint for understanding how databases work under the hood.
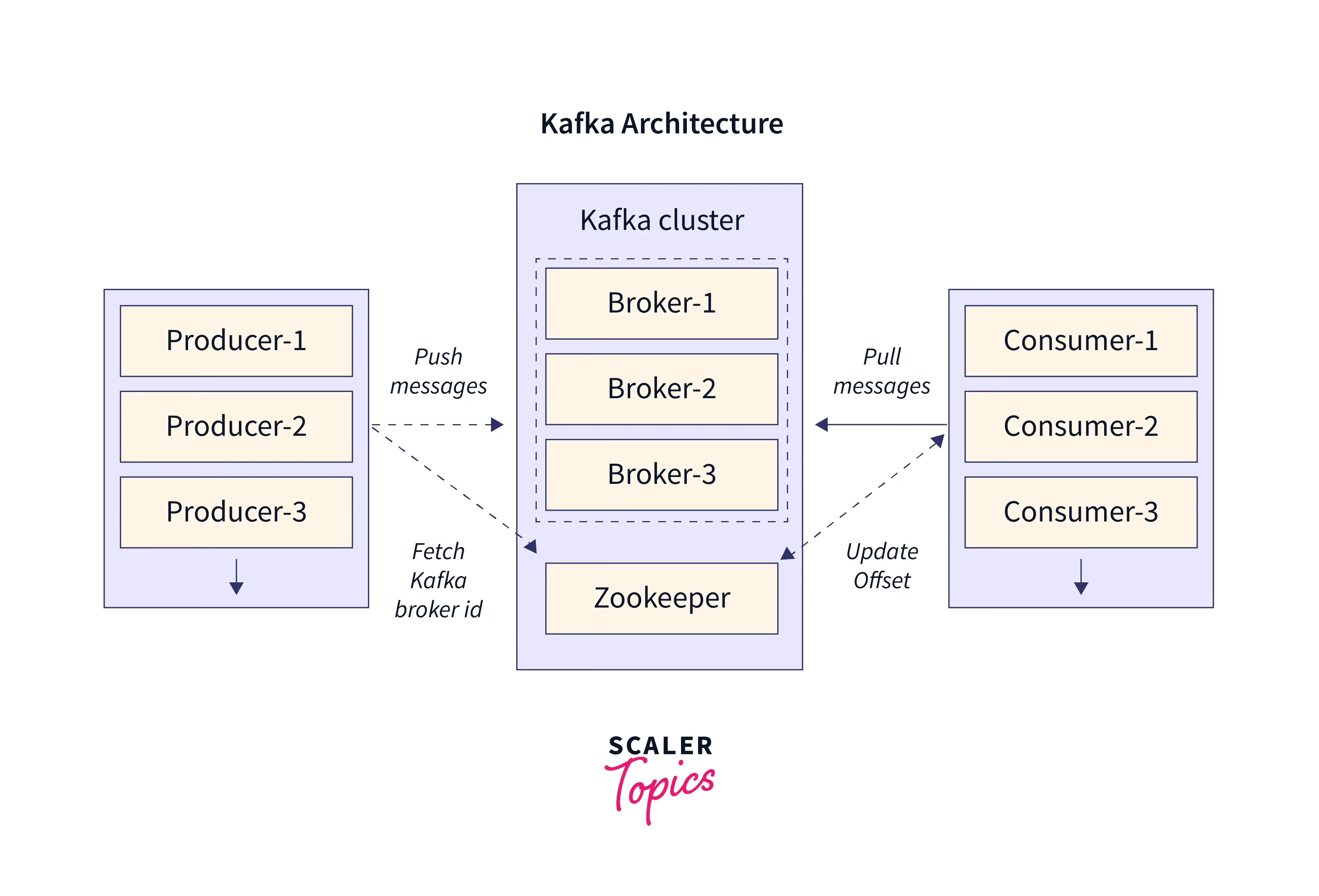
Kafka: a Distributed Messaging System for Log Processing

Kafka was introduced as a high-throughput, distributed messaging system designed for log data by Linkedin. This paper outlines its architecture and how it decouples producers and consumers while providing fault tolerance and scalability, forming the backbone of many real-time data pipelines.
Bigtable: A Distributed Storage System for Structured Data
Google’s Bigtable paper describes a distributed, sparse, and scalable data storage system that supports structured data. It underpins services like Google Analytics and Search, and inspired open-source projects such as HBase and Cassandra
Dynamo: Amazon’s highly available key-value store

Amazon’s Dynamo paper presents a distributed key-value storage system optimized for high availability and scalability. It introduced techniques like eventual consistency, consistent hashing, and vector clocks, influencing systems like Cassandra, Riak, and DynamoDB.
If you would like to read more this type of papers you can check the Git repository which is created by Reynold Xin- cofounder of Databricks: https://github.com/rxin/db-readings?tab=readme-ov-file
If you enjoyed it, consider subscribing to this newsletter grow!