
The Ultimate Guide to Change Data Capture Tools: Choosing the Right CDC Solution in 2025
Comparison of different CDC tools

Change Data Capture (CDC) has become the backbone of modern data architectures, enabling real-time data synchronization between systems. But with so many options available, how do you choose the right tool for your organization? I’ve analyzed the leading CDC solutions to help you make an informed decision.
The CDC Revolution
Traditional data integration relied on batch processing – ETL jobs that ran nightly or hourly, leaving businesses operating on yesterday's data. CDC changed everything by monitoring database transaction logs and streaming changes as they happen. Instead of asking "What changed since last night?", CDC answers "What just changed?" in real-time.
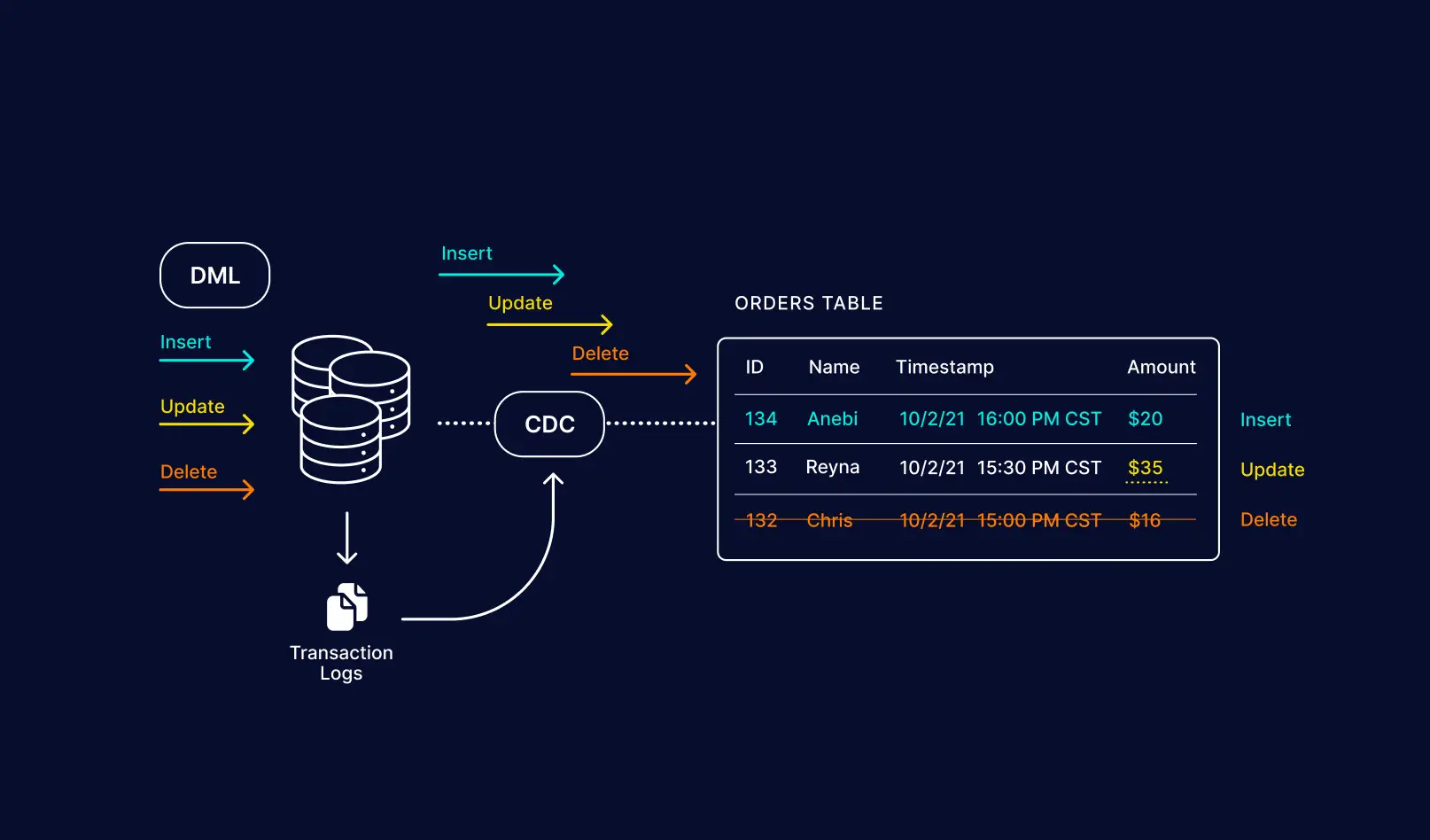
So when you make a change in the database let’s say :
You have a customer database table:
ID Name Email
1 Alice alice@email.com
2 Bob bob@email.comChanges:
Bob updates his email.
A new customer, Carol, is added.

This output can be sent to analytics systems, caches, or data lakes for real-time updates.
Why Low Latency Matters for Streaming
Modern dashboards need live metrics, not hour-old snapshots. A 5-second delay in detecting a system outage could mean millions in lost revenue. Organizations using real-time CDC report:
60% faster decision-making with live dashboards
40% reduction in customer service issues due to data consistency
25% improvement in fraud detection accuracy
Significant cost savings from preventing data-driven errors
But with great power comes great complexity. The CDC tool you choose will determine whether you achieve these benefits or struggle with operational overhead. Let's explore your options.
🔧 Open Source Champions
Debezium + Kafka The streaming powerhouse
Debezium transforms your database transaction logs into Kafka streams, offering true real-time CDC with sub-second latency. Built on Kafka Connect, it supports virtually every major database and integrates seamlessly with the Kafka ecosystem.
Best for: Teams already invested in Kafka infrastructure
Strengths: Zero licensing costs, highly flexible, mature community
Watch out for: Operational complexity, requires Kafka expertise, at-least-once delivery only
Latency: ~0.5 – 2 seconds
Cost: Free (infrastructure costs apply)
Architecture: Debezium runs as Kafka Connect source connectors on a Kafka Connect cluster. Each connector (MySQL, Postgres, Mongo, etc.) connects to its source DB’s log (binlog or logical stream) and writes change events to Kafka topics. Kafka Connect offset topics (or an external store) track connector state. Debezium also supports a standalone Debezium Server (no Kafka) to send events to Kinesis, Pub/Sub, Pulsar, etc. Users often build full pipelines by pairing Debezium (CDC) sources with Kafka Connect sinks.

Apache Flink CDC The exactly-once guarantee
Flink CDC combines the power of Apache Flink's stream processing with robust CDC capabilities. It's the only open-source solution offering true exactly-once semantics out of the box.
Best for: Organizations needing complex real-time transformations
Strengths: Exactly-once processing, automatic schema evolution, extremely low latency
Watch out for: Steep learning curve, requires Flink cluster management
Latency: Sub-second (often <100ms)
Cost: Free (infrastructure costs apply)
Architecture: A Flink cluster executes Flink CDC jobs defined via YAML or code. Each job uses Flink’s DataStream API (or Table API) with a CDC source connector. The job can incorporate transformations and connect to sinks (e.g. Kafka, JDBC, Iceberg). Flink CDC can run in streaming mode for continuous flow. It also supports batch operation by scanning static data or performing periodic snapshots. State (offsets, transformation state) is managed by Flink’s checkpointing and state backends (e.g. RocksDB).
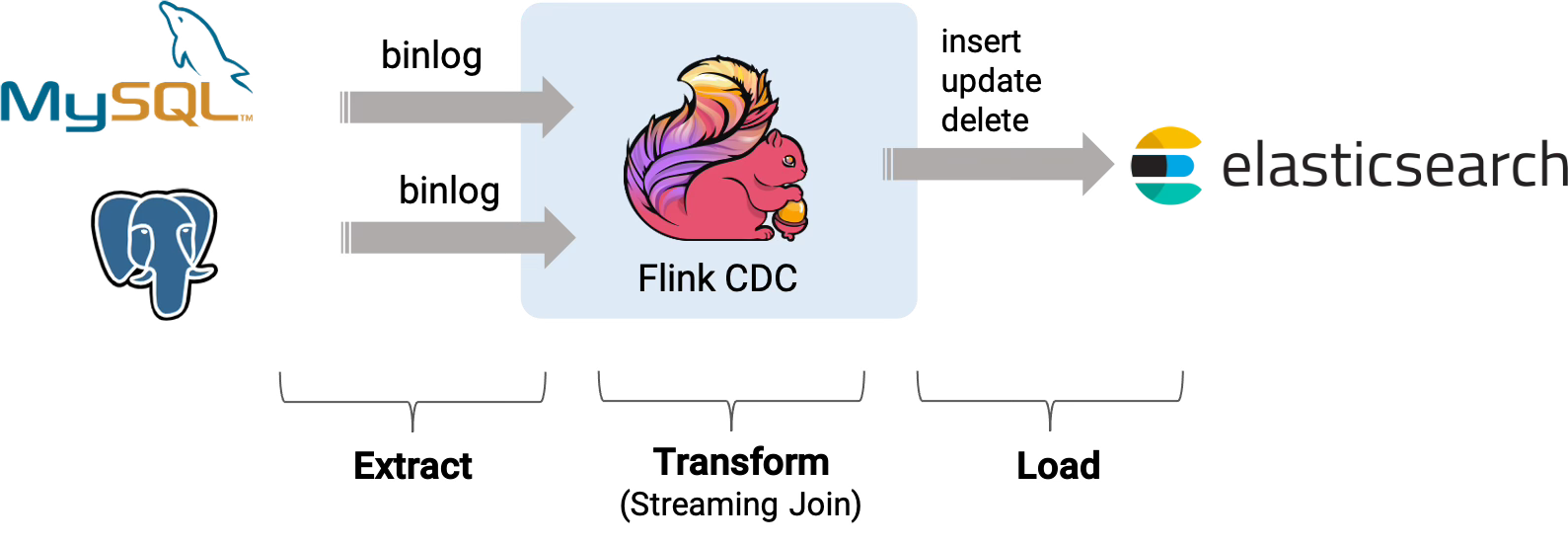
Airbyte The connector ecosystem
With 400+ connectors, Airbyte democratizes data integration. While not purely streaming (it runs frequent batch jobs), it's user-friendly and cost-effective for many use cases. However I think for pure streaming this is not a good solution because it is very slow.
Best for: Startups and teams wanting low-cost, easy setup
Strengths: Massive connector library, user-friendly UI, open-source with cloud option Watch out for: Batch-oriented approach, 5+ minute minimum intervals
Latency: 5+ minutes
Cost: Free self-hosted, usage-based cloud pricing
Architecture: A central Airbyte server (cloud service or self-hosted) orchestrates jobs. Connectors run in Docker containers. Users configure sources and destinations in the UI (or via API). For CDC sources, Airbyte schedules frequent sync jobs (it treats CDC sources as regular syncs at high frequency). There’s no persistent streaming – each sync job pulls changes since the last sync.
🏢 Enterprise Solutions
Fivetran (Commercial SAAS)
Architecture: Fully-managed SaaS. Fivetran separates the user’s environment, Fivetran cloud, and customer cloud for security and performance. When a connector sync is due, Fivetran’s backend spins up transient worker processes (in Fivetran-managed infrastructure) to extract and load data. In practice, users log in to Fivetran’s dashboard to create connectors. The Fivetran control plane stores configuration, and its execution engine (workers) handles the actual data movement. Fivetran uses parallelization on-demand to maximize throughput.
Best for: Organizations prioritizing reliability and support over cost
Strengths: Zero maintenance, automatic schema handling, comprehensive connector catalog
Watch out for: High costs at scale, vendor lock-in, black-box operations
Latency: Sub-5 minutes
Cost: Usage-based (can be expensive)
I think for very low-latency (sub-1-minute) or custom pipelines, Fivetran may not be ideal.
Qlik Replicate (Attunity)
A mature, GUI-driven solution designed for mission-critical enterprise replication. Offers exactly-once delivery and supports even mainframe systems.
Best for: Large enterprises with complex, heterogeneous environments
Strengths: Exactly-once guarantees, minimal source impact, comprehensive enterprise features
Watch out for: High licensing costs, Windows-centric, heavyweight for small projects Latency: Sub-second to seconds
Cost: High (perpetual licenses)
Architecture: Typically installed as a server with agent components. Qlik has a listener that taps DB transaction logs (or triggers) and an in-memory engine that stages changes. It features two data paths: an ongoing CDC stream for updates and a batch loader for full loads/backfills. A central checkpoint store tracks progress for exactly-once delivery. Configuration is done via a GUI or CLI.
☁️ Cloud-Native Options
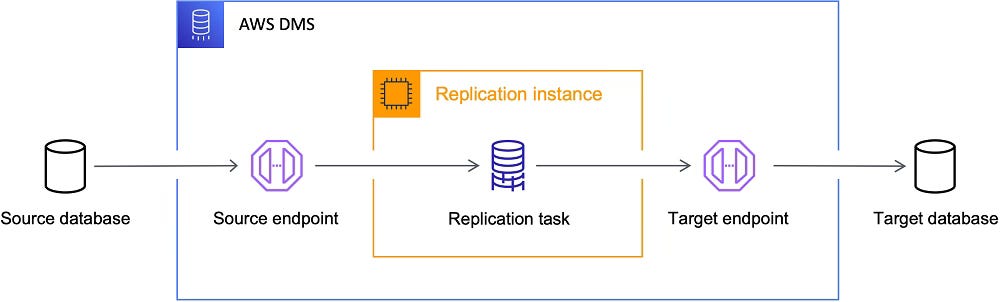
AWS DMS
AWS DMS is a managed cloud service for migrating and replicating databases. It supports both full load and ongoing CDC for many sources and targets.
Best for: AWS migrations and simple replications
Strengths: Fully managed, good for AWS ecosystems, handles legacy sources
Watch out for: Limited to AWS targets, higher latency, frequent task failures reported Latency: Not sub-second; typical latency might be seconds to minutes
Cost: Per-hour instance pricing
Architecture: AWS-managed. You create “tasks” that run on DMS replication instances (AWS EC2 under the hood). The instance connects to a source DB and target. DMS handles log-reading (CDC) internally. Architecture is serverless from the user’s perspective (AWS scales the replication instance).
AWS itself notes that DMS “is not a streaming system” and that latency can vary and is hard to monitor
🎉 BONUS
Estuary Flow The exactly-once innovator
Estuary Flow is a unified streaming/batch data platform. It uses a custom DSL (Flow) to define pipelines that capture, transform, and load data. Its core is Gazette (open-source) which manages the data streams (Collections). Flow can do CDC, batch, and real-time analytics in one model.
Best for: Organizations needing guaranteed exactly-once delivery with multiple targets
Strengths: True exactly-once end-to-end, automatic schema evolution, unified real-time/batch
Watch out for: Newer ecosystem, primarily commercial offering
Latency: <100ms
Cost: Usage-based with free tier
Architecture: Flow pipelines run on Estuary’s control plane (SaaS) and data plane (can be public or private cloud, or on-prem). A pipeline attaches to source systems (e.g. database tables or logs) and continuously reads changes. Internally, every source stream is stored in Collections (append-only log). One collection per source/table, which can then be read by multiple sinks. A Flow app can write to multiple targets from the same source collection. Underneath, Estuary provides connectors for many sources/targets, and a “Kafka emulation” (Dekaf) if needed.
I think this one is truly designed for real-time streaming. It captures every change exactly once as it happens (via DB WAL or log streaming). It also supports batch backfills: you can initiate a snapshot that will emit historical data into the collection. Crucially, real-time and historical data are unified in the same pipeline.
Conclusion
Choosing the right CDC solution is all about balancing your organization’s priorities—latency, complexity, cost, and ecosystem fit. Ultimately, real-time CDC is no longer a luxury but a necessity for data-driven businesses. By aligning your CDC tool with your team’s skills, infrastructure, and performance targets, you’ll unlock faster insights, more dependable reporting, and a decisive edge in a world where “what just changed?” matters more than ever.