
HyperLogLog: The Probabilistic Algorithm That's Faster Than Exact Counting
The smarter way to count distinct values in massive datasets

I'm Subhan Hagverdiyev and welcome to Dataheimer - where we explore the atomic impact of data.
Just like splitting an atom releases enormous energy, the right data engineering decisions can transform entire organizations.
This is where I break down complex concepts and share all the fascinating discoveries from my journey.
Want to join the adventure? Here you go:

In the world of big data analytics, counting distinct elements efficiently is a fundamental challenge.
Traditional methods like COUNT(DISTINCT) in SQL can be computationally expensive and memory-intensive when dealing with massive datasets. This is where HyperLogLog (HLL) comes to the rescue—a probabilistic data structure that can estimate the cardinality (number of unique elements) of large datasets with remarkable accuracy while using minimal memory.
The algorithm has been widely adopted across the database ecosystem, from traditional SQL databases to NoSQL systems, distributed query engines, and cloud data warehouses. This widespread adoption demonstrates its universal value for cardinality estimation in modern data processing.
Origins and History
The algorithm has its roots in academic research dating back to the 1980s. Philippe Flajolet and G. Nigel Martin introduced the foundational concepts in their 1984 paper "Probabilistic Counting Algorithms for Data Base Applications", which led to the Flajolet-Martin algorithm.
The evolution continued with Flajolet developing the LogLog algorithm in 2003, followed by SuperLogLog. Finally, HyperLogLog emerged as an extension of the earlier LogLog algorithm, offering improved accuracy and efficiency.
How HyperLogLog Works
HyperLogLog operates on a clever mathematical principle: it analyzes the patterns in hashed values to estimate cardinality. The algorithm works by:
1. Hashing:
Each input element is hashed to produce a uniform bit pattern
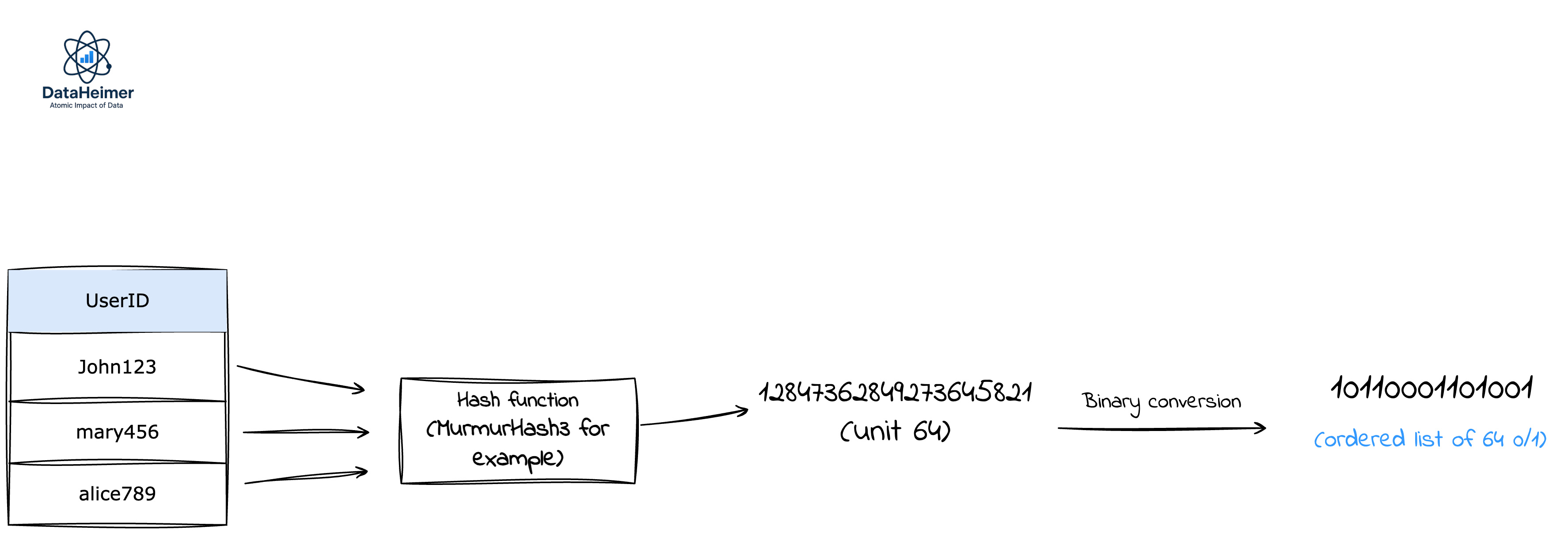
2. Leading Zero Analysis
Here's where HyperLogLog gets sophisticated. Instead of using the entire hash, we split it into two parts:
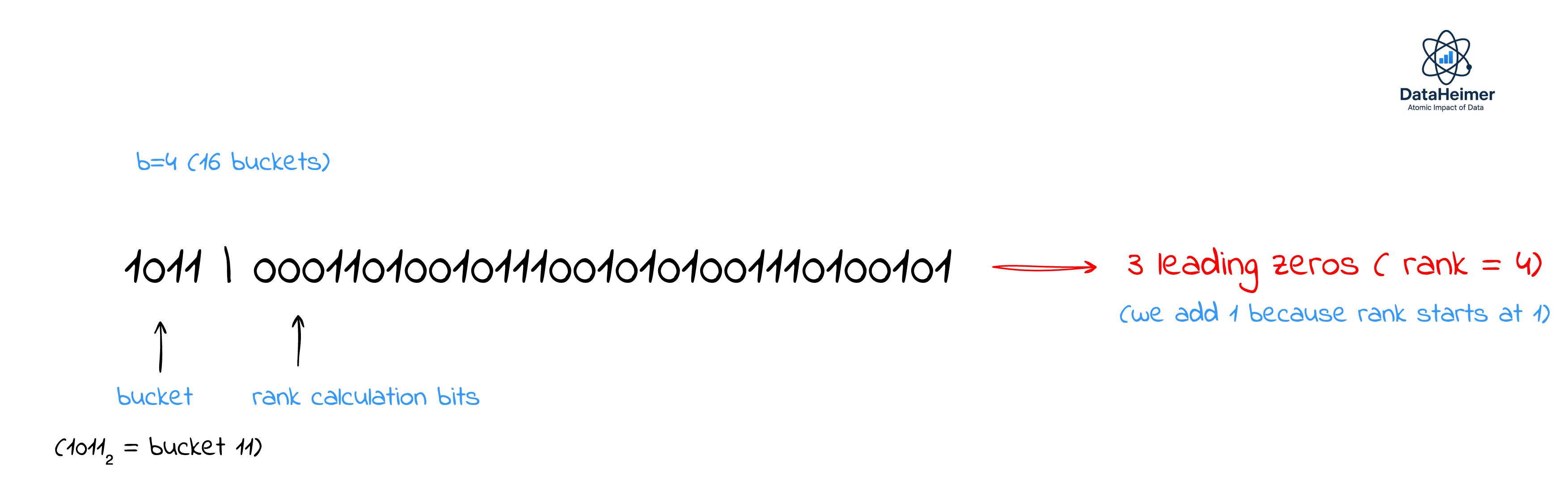
Part 1: Bucket Selection (first b bits)
Use the first
bbits to determine which bucket this element belongs toThis creates 2^b buckets (typically b=4 to b=16)
Each bucket will maintain its own statistics
Part 2: Rank Calculation (remaining bits)
Use the remaining (64-b) bits to calculate the rank
For each hash, count the number of leading zeros in its binary representation. This becomes your "rank" for that element.
The mathematical insight: In a uniform random distribution, the probability of seeing exactly k leading zeros is 2^(-k-1). So if you observe k leading zeros, you've likely seen about 2^k unique elements.
Each bucket keeps track of the maximum rank it has seen:
Bucket 0: max_rank = 3
Bucket 1: max_rank = 7
Bucket 2: max_rank = 2
...
Bucket 15: max_rank = 53. Final Cardinality Estimate
The final estimate uses the harmonic mean of all bucket estimates to reduce variance:
Why harmonic mean? Regular averaging would be dominated by buckets with very high ranks (outliers). The harmonic mean is more robust to outliers and provides better estimates
Key Advantages
Memory Efficiency
The Redis HyperLogLog implementation uses up to 12 KB and provides a standard error of 0.81%. This means you can estimate the cardinality of billions of unique elements using just 12 KB of memory—a remarkable feat compared to traditional exact counting methods.
Scalability
Traditional exact unique counting in SQL uses O(unique elements) additional memory, making it impractical for large datasets. HyperLogLog uses constant memory regardless of the dataset size.
Accuracy
Despite being probabilistic, HyperLogLog provides highly accurate estimates. The error for very small cardinalities tends to be very small, making it suitable for real-world applications.
HyperLogLog Across Database Systems
PostgreSQL: One of the first major SQL databases to embrace HyperLogLog through extensions like postgresql-hll, enabling efficient cardinality estimation for analytical workloads.
Microsoft SQL Server: Implements approximate distinct counting capabilities that leverage HyperLogLog principles in functions like APPROX_COUNT_DISTINCT.
Oracle Database: Provides HyperLogLog functionality through various approximate query processing features for large-scale analytics.
Distributed Query Engines
Presto/Trino: Facebook implemented HyperLogLog in Presto with the APPROX_DISTINCT function, reducing query times from days to hours for large-scale cardinality estimation.
Apache Spark: Integrates HyperLogLog through various libraries and built-in functions for distributed data processing.
Apache Drill: Supports HyperLogLog for efficient approximate distinct counting in distributed environments.
Cloud Data Warehouses
Google BigQuery: Provides comprehensive HLL functions (HLL_COUNT.EXTRACT, HLL_COUNT.MERGE) for large-scale analytics workloads.
Amazon Redshift: Implements approximate distinct counting using HyperLogLog-based algorithms.
Snowflake: Offers HLL functions for efficient cardinality estimation in cloud data warehousing scenarios.
Azure Synapse Analytics: Includes HyperLogLog-based approximate functions for big data analytics.
NoSQL and Specialized Systems
Redis: Popularized HyperLogLog with simple PFADD, PFCOUNT, and PFMERGE commands, making it accessible to application developers.
Apache Druid: Uses HyperLogLog for real-time analytics and approximate cardinality queries.
ClickHouse: Implements various HyperLogLog variants optimized for analytical workloads.
Elasticsearch: Provides cardinality aggregations based on HyperLogLog for search analytics.
SQL Usage Examples
Here are typical SQL pattern that could be used in real-world in Snowflake. Let’s say we are calculating user retention:
CREATE OR REPLACE TABLE user_activity AS
SELECT
DATEADD(day, UNIFORM(0, 29, RANDOM()), '2024-01-01')::DATE as activity_date,
UNIFORM(1000, 9999, RANDOM()) as user_id,
UNIFORM(1, 10, RANDOM()) as page_id
FROM TABLE(GENERATOR(ROWCOUNT => 100000));We will calculate daily active users using HLL:
CREATE OR REPLACE TABLE daily_active_users AS
SELECT
activity_date,
HLL_BUILD_AGG(user_id) as user_hll_sketch
FROM user_activity
GROUP BY activity_date
ORDER BY activity_date;For weekly active users calculation using HLL union:
SELECT
DATE_TRUNC('week', activity_date) as week,
HLL_ESTIMATE(HLL_COMBINE(user_hll_sketch)) as estimated_wau
FROM user_activity ua
WHERE DATE_TRUNC('week', ua.activity_date) = DATE_TRUNC('week', dau.activity_date)) as exact_wau
FROM daily_active_users dau
GROUP BY DATE_TRUNC('week', activity_date)
ORDER BY week;
Limitations and Considerations
Approximation Nature
HyperLogLog provides estimates, not exact counts. While the error rate is typically low (around 0.81%), applications requiring exact counts should use traditional methods.
Small Dataset Accuracy
For very small datasets (fewer than 100 unique elements), exact counting might be more appropriate as the memory savings of HyperLogLog are minimal.
Hash Function Dependency
The accuracy of HyperLogLog depends on the quality of the hash function used. Poor hash functions can lead to biased estimates.
Use Cases and Applications
Web Analytics
Counting unique visitors to websites
Tracking distinct page views
Measuring user engagement across different time periods
Database Analytics
Estimating table cardinalities for query optimization
Monitoring data distribution in large datasets
Real-time analytics dashboards
Stream Processing
Counting unique events in real-time data streams
Monitoring distinct users in live applications
Fraud detection systems
Data Warehousing
ETL pipeline optimization
Data quality assessment
Historical trend analysis
Conclusion
Depending on your use case (some of them can't stand approximation!), HyperLogLog can be an incredibly useful thing in your toolbox!
HyperLogLog is particularly efficient at estimating the cardinality of large datasets:
with relatively high accuracy (typically ~0.81% error rate)
while using a small amount of memory and CPU (~12KB memory vs gigabytes for exact counting)
enabling real-time analytics that would otherwise be impossible (queries finishing in minutes instead of hours)
Whether you're tracking daily active users, analyzing click streams, or optimizing database queries, HyperLogLog offers that sweet spot between accuracy and performance that makes big data analytics actually feasible. Just remember: when you absolutely need exact counts, stick with traditional methods—but for everything else, HLL is your friend!
Thank you for reading this far. See you in my next articles. Don't forget to subscribe to get more of this interesting data engineering content!"