
Hash Tables vs B+ Trees: Why Databases Choose "Good Enough" Over Perfect
Why every major database defaults to B+ trees

I'm Subhan Hagverdiyev and welcome to Dataheimer - where we explore the atomic impact of data.
Just like splitting an atom releases enormous energy, the right data engineering decisions can transform entire organizations.
This is where I break down complex concepts and share all the fascinating discoveries from my journey.
Want to join the adventure? Here you go:

At first glance, hash tables seem like the obvious winner when choosing a data structure for database indexing. After all, they offer O(1) lookup time for exact matches—how can anything compete with that? B+ trees, by contrast, offer O(log n) performance, which feels sluggish in comparison.
But here's what's puzzling: PostgreSQL, MySQL, Oracle, and virtually every major database system defaults to B+ trees for their primary indexes. Are these billion-dollar companies making a fundamental performance mistake?
Spoiler alert: They're not.
Intro
Despite their O(1) lookup time , hashmaps are not preferred in database indexing. Because in real world , databases are asked to do more than just find a single record by its exact key.
Hash tables excel at one thing: fast, exact key lookups. But they fall flat when we need:
Range queries (e.g., "find all users registered between January and March")
Sorting (e.g., "order by last name")
Prefix or partial matches (e.g., "name starts with 'Al'")
B+ trees, on the other hand, gracefully support all of the above. Their structure maintains data in sorted order, enabling efficient in-order traversal, range filtering, and even multi-level indexing with minimal overhead.
We will now explore their strength and internal structure
Disclaimer: We won’t go into too much detail while explaining each of them since our goal is to find out why databases prefer one over another for indexing. If their will be interest I will write about each of them in depth on next articles.
Hash table
Let's start with what everyone learns in algorithms class:
A hash table is a data structure that maps keys to values using a hash function to compute an index into an array of buckets or slots.
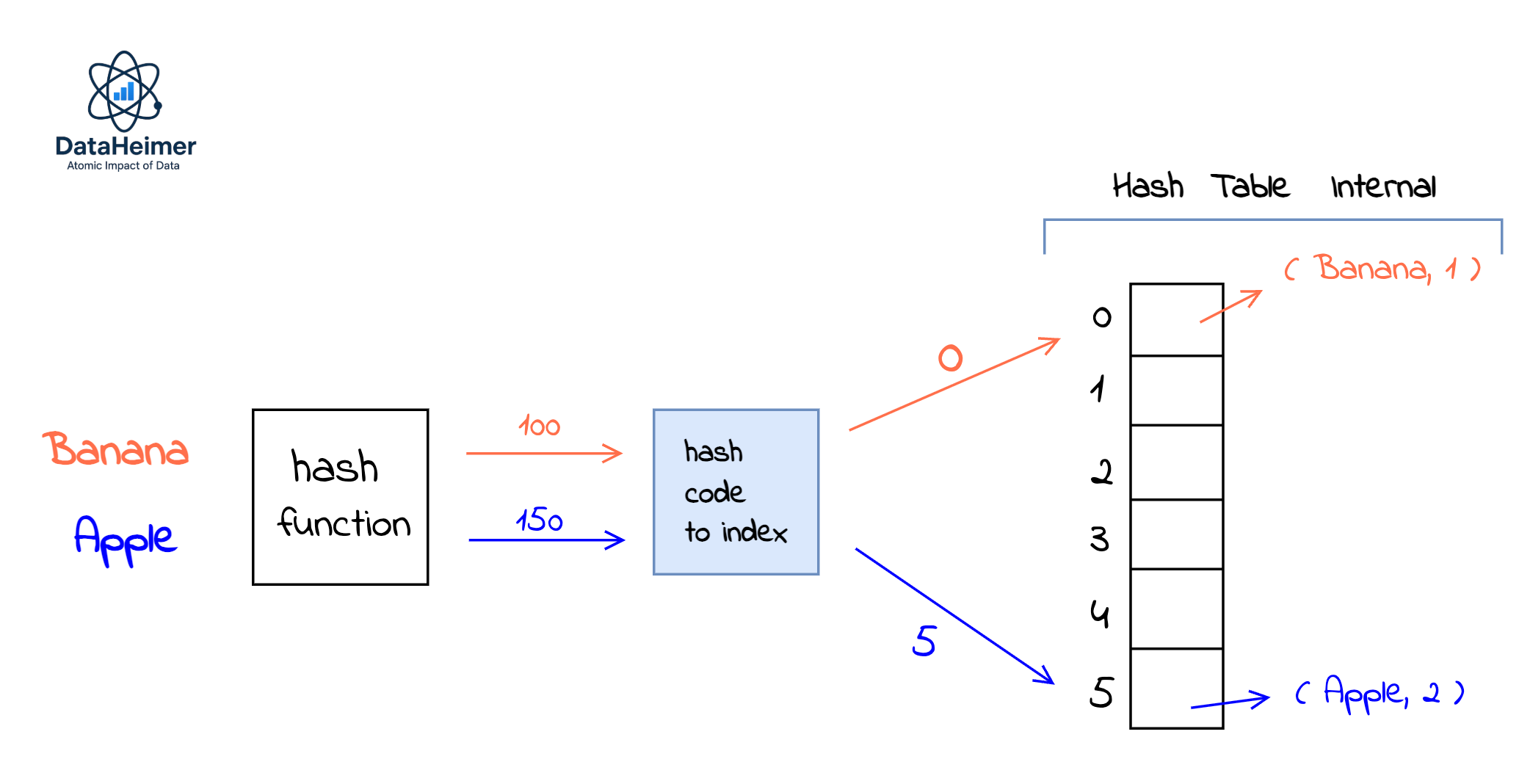
Let’s say we have 2 key-value pairs (Banana, 1) and (Apple, 2). We pass each key to the hash function and the hash function returns a numeric hash code( for example "Banana" → 100, "Apple" → 150). Then the hash code is converted to a valid array index by taking it modulo the array size. In our case the array size is 6:
100 % 6 = 0 → index for "Banana"
150 % 6 = 5 → index for "Apple"
Each index stores key-value pairs:
Index 0 → ("Banana", 1)
Index 5 → ("Apple", 2)
Since the hash codes map to different indices (0 and 5), there is no collision.
However collisions happen when two keys hash to the same index:
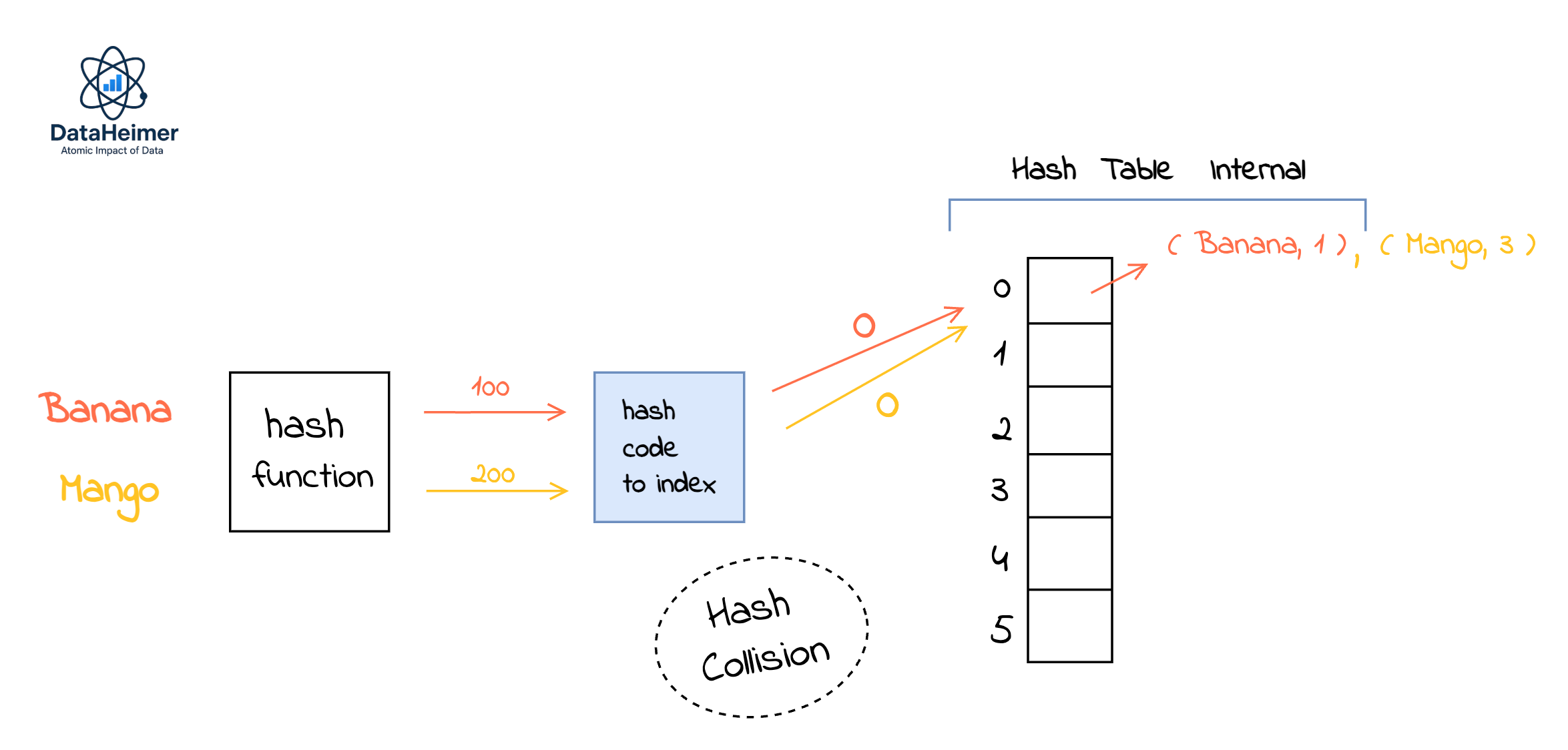
We are now adding (Mango, 3) pair and both hash codes(100, 200) points to index 0. There are several different ways of addressing collisions. The most common one is simply to store all the objects that get assigned to the same index in a linked list. In this scenario, instead of simply storing the value at that index, the linked list must contain both the entire key and the value in pairs instead of just the value, so that the values can be uniquely tied to a key.
Performance:
Average Case Lookup: O(1)
With a good hash function and low collision rate, lookup, insert, and delete operations take constant time.
Best Case: Lightning fast
If there are no collisions, the operation is almost instantaneous.
Worst Case: O(n)
If the hash function causes many collisions or the table is poorly sized, performance can degrade to linear time.
B+ Trees:

A B+ tree is a type of self-balancing tree data structure. Unlike a regular B-tree, a B+ tree separates its “table of contents” from its actual “content pages”
In B+ trees we keep all our actual data at the bottom level (leaf nodes) and use the upper levels purely for navigation
[7][17][25] represent our root nodes. These are pure navigation aids – they contain key values that guide our search but don't store actual data. Think of them as highway signs pointing us in the right direction.
[1][4] → [7][10] → [17][19][21] → [25][31] are our leaf nodes. These contain the actual data (or pointers to the actual data).
The Magic of B-Tree Search
Here's where it gets interesting. When we search for a value, the B-tree doesn't check every single piece of data. Instead, it uses those key values as a roadmap:
Looking for the number 19?
Start at the root: [7][17][25]
Since 19 > 17 but < 25, follow the path between 17 and 25
Land directly at the leaf node [17][19][21]
Found it! Only 2 steps instead of potentially searching through dozens of records.
These linked leaf nodes in the diagram are the reason B+ tree can have super fast range queries.If we need all records between 10 and 21? We just need to find the starting point and follow the links. No more tree traversal needed!
Performance:
All Operations (Search, Insert, Delete): O(log n)
Each operation takes logarithmic time because the tree remains balanced, and each node can have multiple children, reducing the tree height.
What Real Applications Actually Need

Let's look at what a typical e-commerce application needs:
-- Exact lookup (Hash tables excel here)
SELECT * FROM users WHERE user_id = 12345;
-- Range query (B+ tree is faster)
SELECT * FROM orders WHERE order_date >= '2025-01-01' AND order_date < '2025-02-01';
-- Sorting (B+ tree is faster)
SELECT * FROM products ORDER BY price ASC;
-- Partial matching (B+ tree is faster)
SELECT * FROM users WHERE email LIKE 'john%';
-- Top-N queries (B+ tree is faster)
SELECT * FROM products ORDER BY rating DESC LIMIT 10;Out of these five common query patterns, hash tables only help with one. B+ trees handle all of them efficiently.
1. Range Queries
B+ trees maintain sorted order, making range scans efficient. Need all orders from January? The B+ tree can find the first January record and scan sequentially to the end.
Hash tables? We'd have to check every single day in January individually.
2. Sorting
Since B+ tree leaves are already sorted, getting ordered results is essentially free. The data is already in the order we need.
Hash tables provide no ordering guarantees. To sort hash table results, we need a separate sorting step.
3. Partial Matches
In the query example we are looking for all emails starting with "john". B+ trees can find the first match and scan forward. Hash tables require scanning the entire table.
4. Memory Efficiency
B+ trees have excellent cache locality. Related data is stored together, reducing disk I/O and improving cache performance.
Hash tables can have poor cache performance due to random access patterns.
Major Databases usage of B+ tree
PostgreSQL's Approach
PostgreSQL offers both hash and B+ tree indexes but defaults to B+ trees for good reason:
-- PostgreSQL's default
CREATE INDEX idx_user_id ON users(user_id); -- Uses B+ tree
-- You can force hash indexes, but rarely should
CREATE INDEX idx_user_id_hash ON users USING HASH(user_id);The hash index is only useful for equality comparisons and doesn't support WAL logging (making it unsuitable for replication).
MySQL's InnoDB Strategy
MySQL's InnoDB engine uses B+ trees exclusively for all indexes. They decided that the consistency and versatility of B+ trees outweighed the potential O(1) benefits of hash tables.
Oracle's Balanced Approach
Oracle uses B+ trees for most indexes but implements hash clusters for specific use cases where we genuinely only need exact lookups.
When Hash Tables Actually Make Sense
So until here we covered for indexing B+ tree definitely wins. However hash tables aren't useless—they excel in specific scenarios:
1. Redis and In-Memory Stores
Redis uses hash tables for O(1) key-value lookups because:
Data fits in memory
Access patterns are primarily exact lookups
Range queries are handled by other data structures (sorted sets, lists)
2. Database Hash Joins
During query execution, databases often build temporary hash tables for join operations:
-- The query optimizer might build a hash table
-- for the smaller table to speed up this join
SELECT * FROM small_table s
JOIN large_table l ON s.id = l.small_id;3. Distributed Systems
Systems like Cassandra use hash-based partitioning to distribute data across nodes, but still use other structures for local storage.
Conclusion
The choice between hash tables and B+ trees in database indexing isn't really about which data structure is "better" in isolation—it's about which one better serves the diverse needs of real-world applications.
While hash tables offer O(1) lookup time, databases aren't just glorified key-value stores. They're complex systems that need to handle everything from exact matches to range queries, from sorting operations to partial text searches. In this broader context, B+ trees emerge as the clear winner for general-purpose indexing.
The logarithmic O(log n) performance of B+ trees might seem inferior to hash tables' constant time operations, but remember: in a well-balanced B+ tree with thousands or even millions of records, we’re typically looking at just 3-4 disk reads to find any piece of data
This is why PostgreSQL, MySQL, Oracle, and other major database systems have converged on B+ trees as their default indexing strategy. They've chosen versatility and consistency over the narrow performance advantage that hash tables provide for exact lookups.
Hash tables still have their place in computing, particularly in in-memory systems, caching layers, and specialized use cases. But for the foundational task of database indexing, B+ trees reign supreme—and now you know why.
Thank you for reading this far. See you in my next articles. Don't forget to subscribe to get more of this interesting data engineering content!"
You could add one more reason that hash tables needs to fit in memory and if we are growing in size then we are out of luck :(